Python in Excel (09) サンプルデータセット
Pythonサンプルを試す
Python in Excelには、すぐに試せるサンプルがあります。
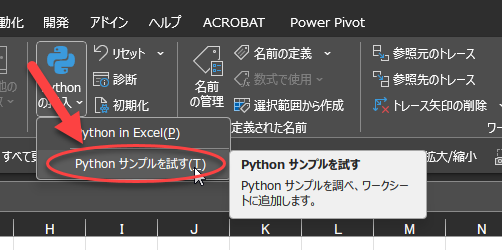
「Pythonの導入」から「Pythonサンプルを試す」を選択すると、右側のウインドウに5つのサンプルが表示されます。
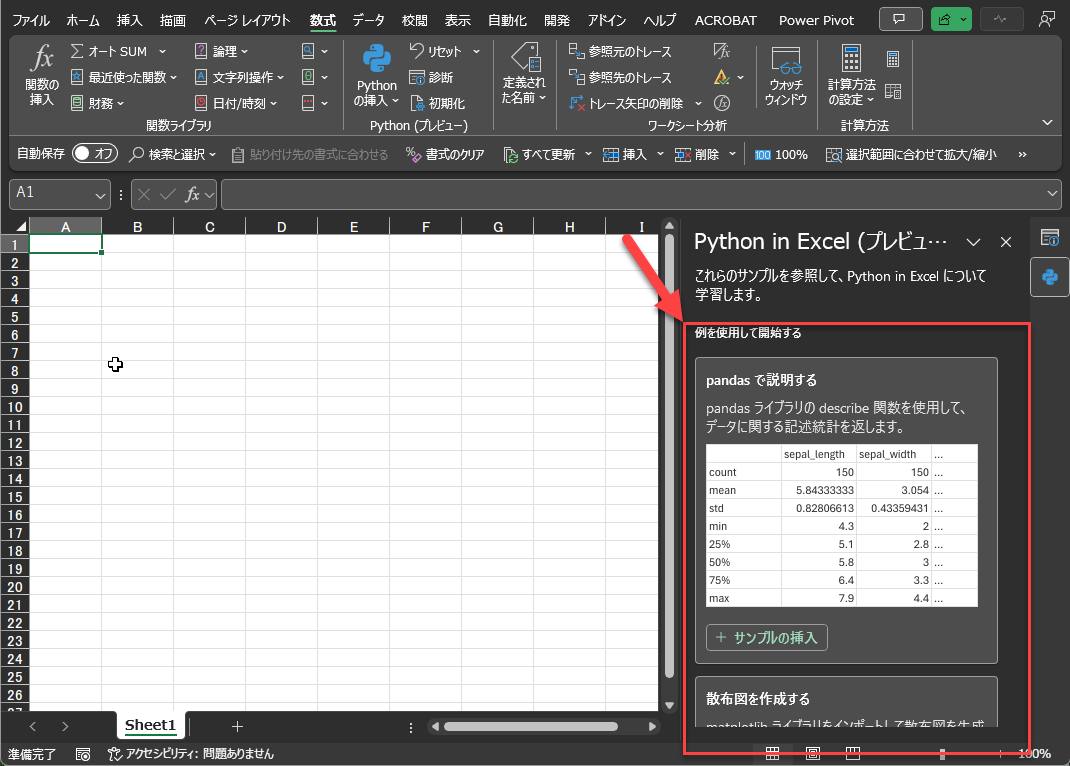
いずれも、機械学習を学ぶためのサンプルとして利用されるIrisデータセットを使用しています。
| サンプル名 | 内容 |
|---|---|
| pandas で説明する | pandasのdescribe()を使って各列ごとの要約統計量を取得する |
| 散布図を作成する | matplotlibを使って散布図を作成する |
| 相関マトリックスを作成する | pandasのcorr()を使って相関係数を計算する |
| ペア プロットを作成する | seabornを使ってペア プロットを作成する |
| 線形会期を生成する | seabornを使って線形会期図を作成する |
データセットには、以下の項目で、150件入っています。
| 項目名 | 内容 |
|---|---|
| sepal_length | がく片の長さ(cm) |
| sepal_width | がく片の幅(cm) |
| petal_length | 花弁の長さ(cm) |
| petal_width | 花弁の幅(cm) |
| soecues | 種 |
種には、setosa(ヒオウギアヤメ), versicolor(ブルーフラッグ), virginica(ヴァージニカ)の3種類があります。
このデータセットは、パターン認識でもっともよく知られているデータセットで、通称Fisher's Iris dataset(フィッシャーのあやめデータセット)と呼ばれています。Creative Commons Attribution 4.0 International (CC BY 4.0) licenseに基づき、自由に使用できます。UCI Machine Learning Repository
ちなみに、サンプルの一番下に、「Python in Excel ドキュメントを表示します。」というリンクがあります。これをクリックすると、Python in Excelのヘルプが表示されます。
seaborn用のサンプルデータセット
seabornは、GitHubに登録されているサンプルデータセットを load_dataset() を使って呼び出すことができますが、Python in Excelは、外部に接続することができないため、利用できません。
scikit-learn (sklearn)用のサンプルデータセット
Toy dataset
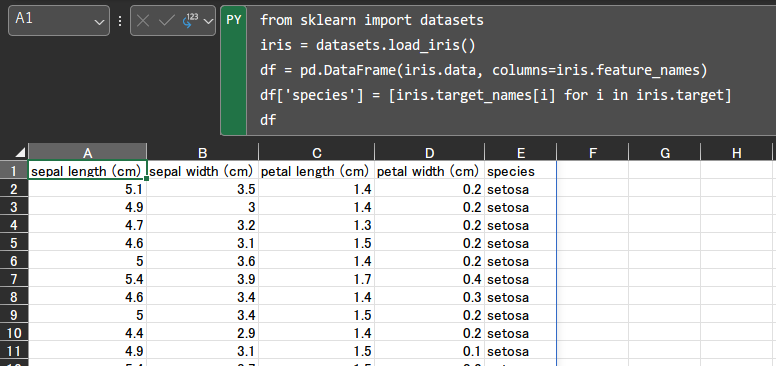
scikit-learnの load_iris() を使って、Irisのデータセットを読み込むことができます。サンプルと同様のデータセットを用意するには、以下のように記述します。
from sklearn import datasets iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = [iris.target_names[i] for i in iris.target] df
この他にも以下のようなサンプルを使用することができます。いずれも機械学習のサンプルとしてよく使われているデータセットです。
| データセット | サンプル名 | 分析方法 |
|---|---|---|
| datasets.load_diabetes() | 糖尿病の診療 | 回帰 |
| datasets.load_digits() | 手書き文字(数字)の認識 | 分類 |
| datasets.load_linnerud() | 生理学的特徴と運動能力の関係 | 回帰 |
| datasets.load_wine() | ワインの識別 | 分類 |
| datasets.load_breast_cancer() | 乳癌の診断結果 | 分類 |
7.1. Toy datasets — scikit-learn 1.3.0 documentation
サンプルデータセット – scikit-learn①【Python】 | BioTech ラボ・ノート
Real world datasets
scikit-learnには、Toy datasetの他にReal world datasetsがありますが、Connection refused となって利用できません。
GitHubなどで公開されているデータセットの利用
Pythonの関数で呼び出すことができませんので、Power Queryで読み込んで利用します。
Python in Excel (04) データ参照 Power Queryで取得したデータ - Excelについての気になったこと